Mortal Coil
Mortal Coil is a puzzle game where the goal is to fill it up a grid completely by moving on it, but without knowing start or end position.
 A Mortal Coil level (colors added by me)
A Mortal Coil level (colors added by me)
The catch is: Once you chose a certain direction, you can't stop and will move until you hit a wall. Here's a playthrough of one of the first levels:

As the levels get higher, the grid size increases and soon it becomes to difficult to solve by hand. I find the puzzle concept so intruiging, I kept coming back around every other year since 2011, trying out new approaches (and also programming languages).
Writing a brute-forcer is pretty straight-forward as you can just try to go every possible direction and see where you end up, and if not solved yet, go back and try the next direction.

You can find a basic brute-force solver with UI here (written in Kotlin): mortal-coil-starter on Github.
Partitioning
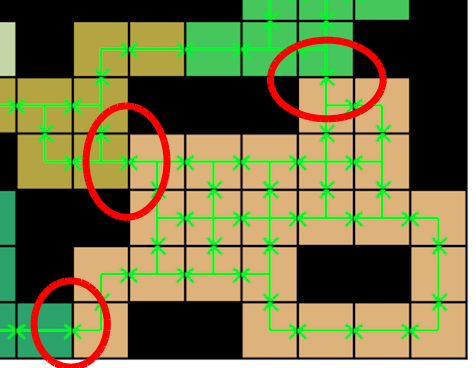
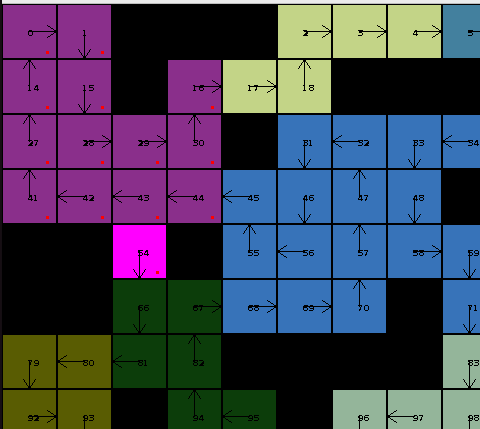
To effectively deal with larger grids, one approach is to do some kind of partitioning. If we try to divide and cut the level into smaller pieces (which I will call caves from now on), we can start solving those pieces of the grid, and then combine the parts together. A possible division of a level could be as follows, indicated by the different colors:
 A partitioned level. Green lines represent all initial possible paths/edges
A partitioned level. Green lines represent all initial possible paths/edges
Now if we have a look at single caves, we can quickly see that some of them have only a limited amount of possible solutions.
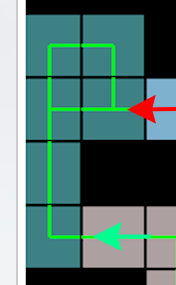
For example here for the turquoise cave we immediately see that it has to be entered from below, because if entered on the upper right, the upper two cells of the cave would be cut off and not be reachable anymore.
This can be generalized to bigger caves with any amount of entries/exits. Another interesting property is that entries and exits are sometimes mandatory (like the lower left), because else a dead end is created in the adjacent cave. The other two entries/exits are optional, as there exist solutions in the other caves that seal the entry so it isn't used at all.
Sometimes this leads to only one solution being possible. In the following cave, only the opening on the left is ignorable, and so the only solution is to enter it from the right and leave it at the lower exit.
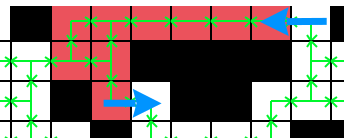
For caves with more openings it gets a bit more complicated, but the principle is still the same: There are some possible solutions to the cave and one of those must be the correct one.
Once all caves are "solved" in isolation, we can then start to connect them to their neighbors and see what solutions are still feasible. If those are then applied this has again an effect on the surrounding caves, and so on, reducing the amount of possibilities:
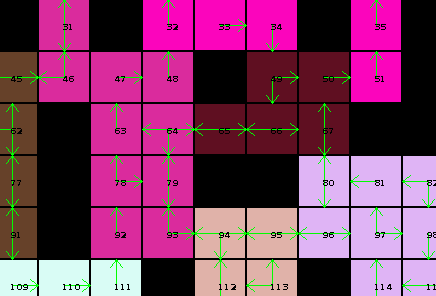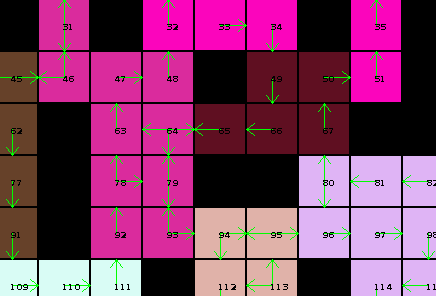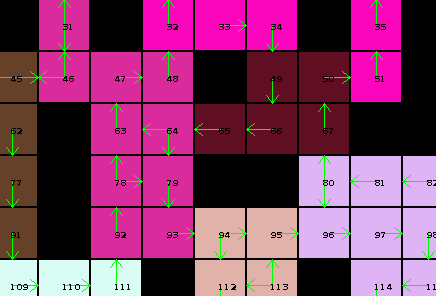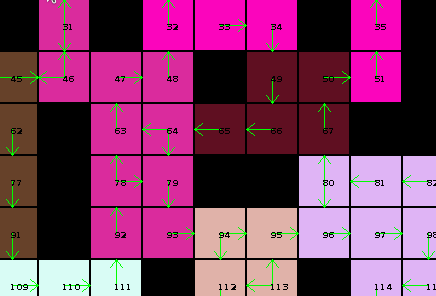
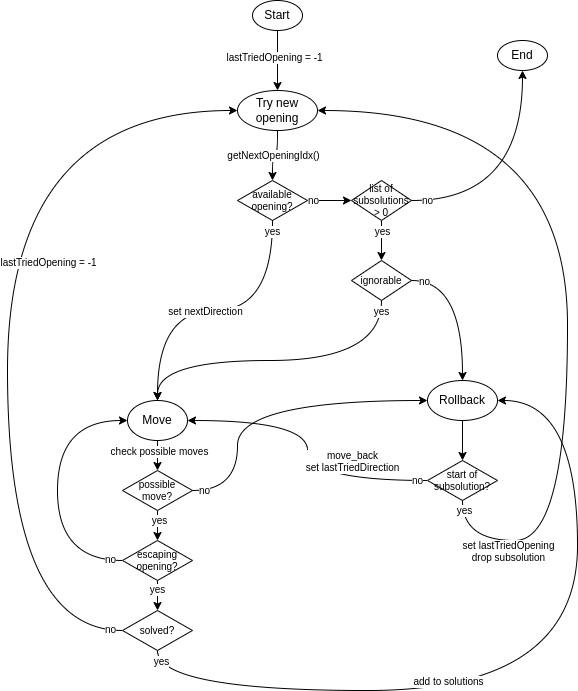
Here's a diagram of my cave solving solution, which basically does this:
- Try a new opening
- Move until either a dead end is found (in which case we roll back)
- Or, if another opening is found, exit the cave and start from 1.
If after leaving an opening the whole cave is filled, we have one of possibly multiple solutions for this caves. By keeping a set of possible solutions we can then reduce the amount of valid edges to what appears in those solutions.
Finding start and end
Now for finding start and end it's a bit tricky, as all of our cave solving implicitly has the assumption that the cave is at one point entered and then left again. But this is not the case with start/end caves, so the tricky part is finding those.
Sometimes it can be simple: The orange cave on top only has one opening, so it has to be either the start or end cave.
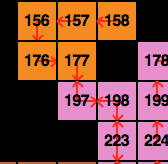
Often after cave solving, we have some caves for which we don't have a solution at all. This comes in handy, as they must be either start or end cave. Here's an example of such a cave, with small red dots as indicators that no solution exists for this isolated cave (pink node 54 is the actual start node here):
Some levels also are tricky because they have solutions for all caves, so it is difficult to find a start. For those, we have to guess the start cave and try, and else do another guess, until the correct start cave is found. For example here, start node 118 and end node 97 are just besides each other, in a cave that would have a solution (if it would be isolated):

Conclusion
 A solved level (with start/end nodes in pink)
A solved level (with start/end nodes in pink)
I'm not entirely sure what kept me coming back to this puzzle, but it was a lot of fun. Sometimes also frustrating, but mostly fun. I think the low entry barrier of with spinning up a brute forcer and watching it solve levels, then see how it gets slower and then improving it really was big part of the fun for me.
I guess also the complexity just hits a sweet spot for me, and the difficulty of finding start and end positions is just a hard problem. Implementing a proper partitioning was hard by itself and I took a long time to get it free of bugs.
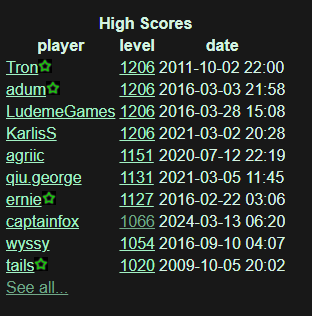
By the way, my current standing on the leaderboards is #11 - for now :-)
 (Yes, at one point in my life, I thought "captainfox" was an extremely cool nickname.)
(Yes, at one point in my life, I thought "captainfox" was an extremely cool nickname.)
Thanks for reading and happy solving!
Edit: While writing this blog post, I was absorbed again by this wonderful puzzle and tuned my solver so it could continue solving for a bit. Turns out I finally made it into the Top 10 :-)