RetroAchievements

This post is part of the Game Boy series (#9).
Last year, I discovered RetroAchievements and had a lot of fun since then.
You can play old games, for example for the Game Boy, in an emulator, and are able to unlock achievements, like finishing a level (or the whole game) or achieving a challenge like finishing a boss damageless or a level with a certain time limit. This is how it looks:
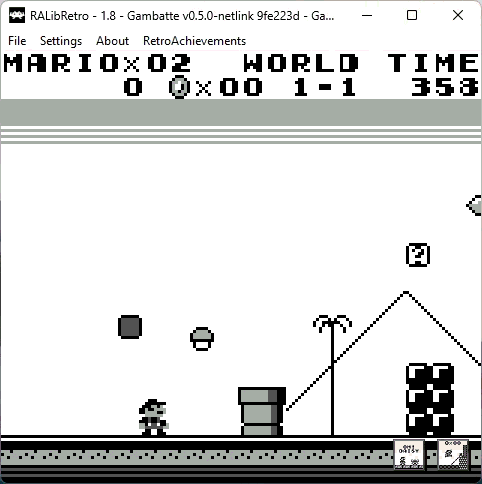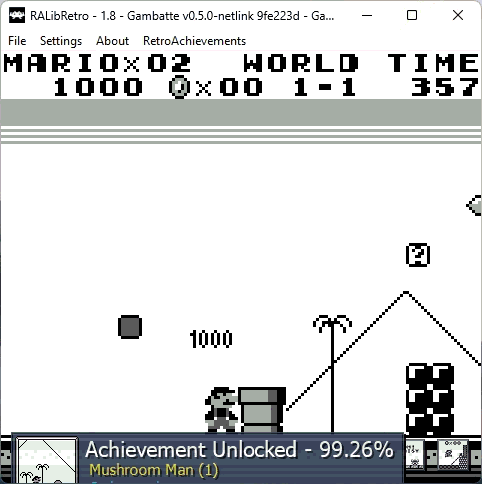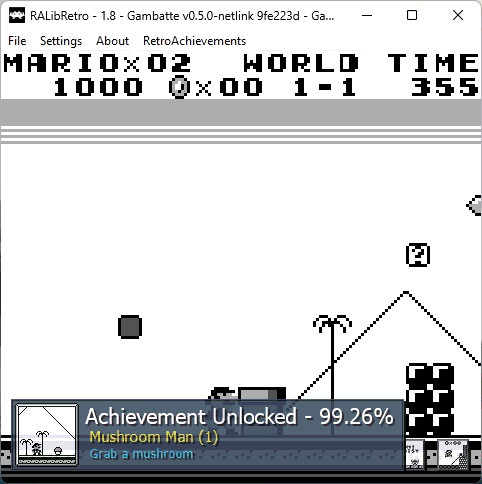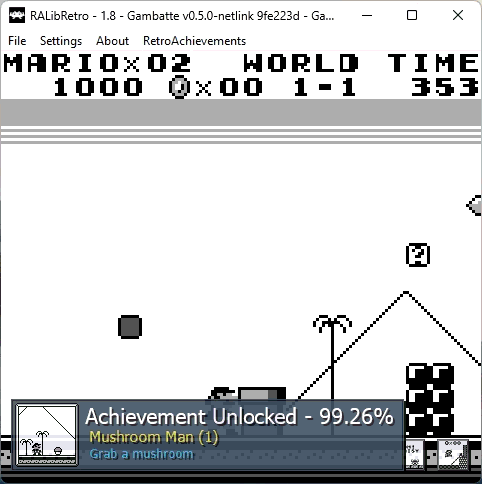
If you beat all challenges and unlock every achievement from a certain game, you get a Mastery badge, looking like this:
Neat, right?
The cool thing is that even some handhelds like the Anbernic RG353V support it (using RetroArch), so it's even possible to play on a handheld and unlock achievements on the go.
Another cool thing is that a many Homebrews (games made nowadays for old consoles) are supported, only for Game Boy there are over 100 Homebrews which have achievements available, see list.
For example, these are all fun GameBoy homebrews worth looking into:
How do games get achievements? Well, simple, someone adds them :-) Under the hood, an achievements consists of a list of conditions, and if all of them are true, the achievement gets triggered.
For the example above with Mario collecting the mushroom, you can imagine something like this:
- Mushroom was collected in this frame
- Mushroom was not yet collected last frame (to avoid triggering multiple times)
- Player is actually playing, e.g. no demo mode is running
These conditions work by checking parts of the internal memory of the emulator when the game is running. Most of the time, before achievements are created, the memory is inspected and annotated, and "Code notes" are added. For example for Super Mario World, we see here the current memory in the middle, and Code notes to the right:
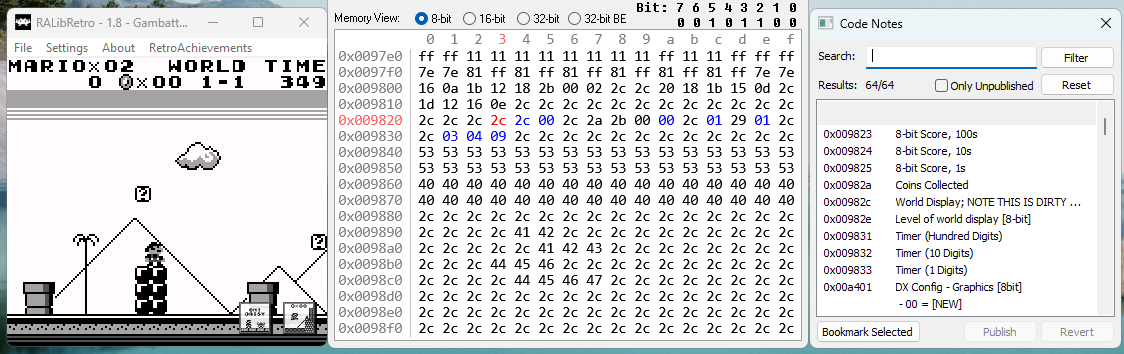
For example, address 0x00982a (in hex notation) tracks the current coins collected, which could be used for example if the player has collected a certain amount of coins.
I contributed a first set to RetroAchievements some months ago, The Rugrats Movie, and I'm currently working on Turok: Battle of the Bionosaurs.
The site also features fun events like Achievement of the Week or RA Roulette where you can play games to collect badges. Be sure to take a look!
Happy retro-gaming!
