Downloading Streams
TLDR: Everything you can stream you can save to a file. It's especially easy to download a specific song from SoundCloud by accessing Google Chrome's cache. A step-by-step guide is at the end of this post.
UPDATE Nov 2014 - As you can see on the webpage they stopped the project :-(
Discovering new music that you like is awesome. That's why I love console.fm:
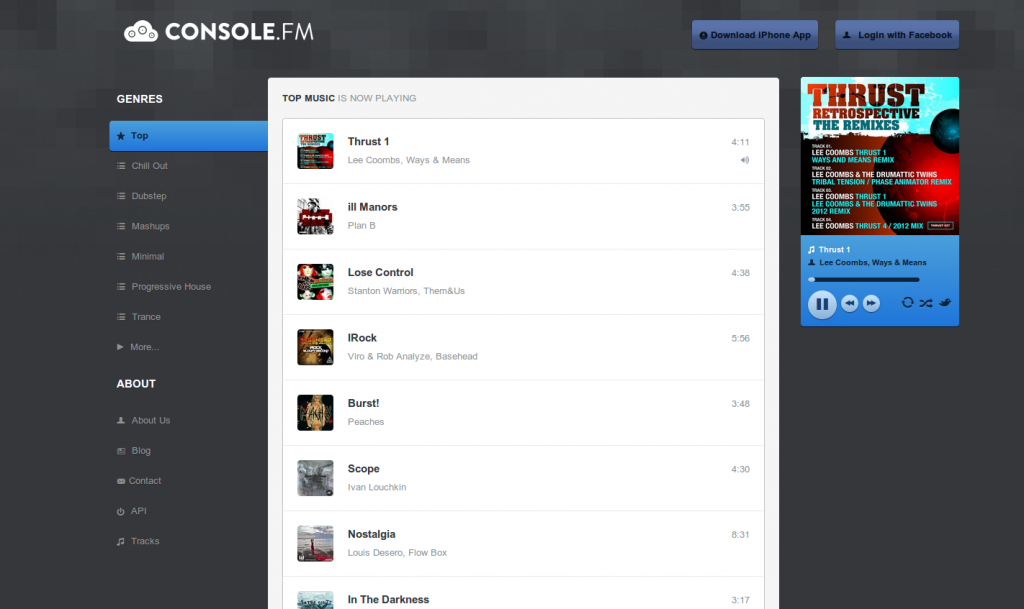
Downloading what you hear
It's just that sometimes you want to download a song, and not just stream it, because you don't know when it will disappear from the list or you have no internet connection. Or you just want to add it to your own music library and playlists.
If you like a song then the best you can do is to support the artist by buying their music. I just want to show that it's really easy to "download" music you're able to stream (as streaming is like downloading in tiny bits).
In this HN Entry, there was a discussion about downloading streams and "If you can stream it, you can download it" is a qoute from there. With enough patience and effort, everything that you can stream you can download too - "For instance you could write a custom audio driver in linux that dumps the bits to a file and then encode that." (Link).
My first approach was searching for code snipplets where an access to the streamed files on console.fm was already documented. I found a Ruby Script (from August 2011) on Github for scraping a certain genre, but it doesn't seem to work anymore. An old HN article implied that there were some security issues in the past and that there had been changes to the API.
Soundcloud
Here's a sample Chrome network log when you visit console.fm:
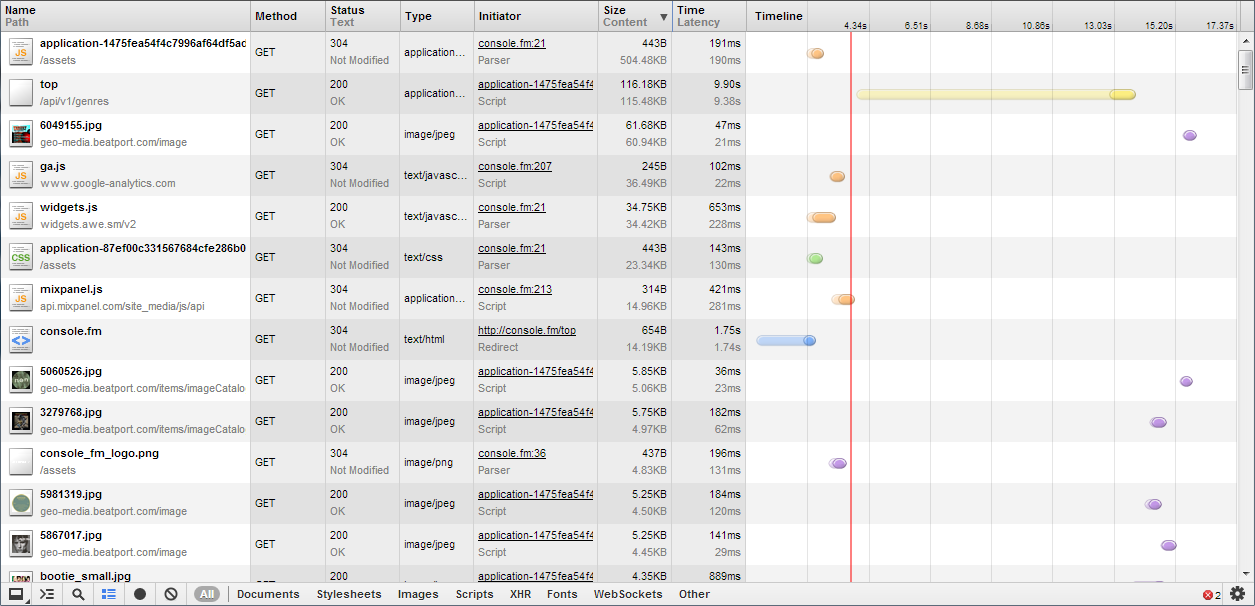
Looking at Chrome's cache, we can easily identify where the song gets fetched (the thing on top which had been loading for nearly 40 seconds :)):
Console.fm is obviously providing content over Soundcloud. Every time a new song is streamed, console.fm sends a GET-request like this:
http://ec-media.soundcloud.com/tqjzeuiN69yn.128.mp3
? ff61182e3c2ecefa438cd02102d0e385713f... etc.
& AWSAccessKeyId = AKIAJ4IAZE5EOI7PA7VQ
& Expires = 1355396974
& Signature = XmG0WErMWP1R5rPjaYQnbNeJqPk%3DThe AWSAccessKeyId always stays the same and seems to be sort of API key for console.fm to access SoundCloud (I found an explanation on Amazon, could be the same thing or that they're using Amazon). I guess the Expires and Signature fields and also the part behind the .mp3 make the link unique and only once "redeemable" (I don't know the exact meaning of the parameters, feel free to correct me). Opening the link directly doesn't work, every link seems to be only valid once.
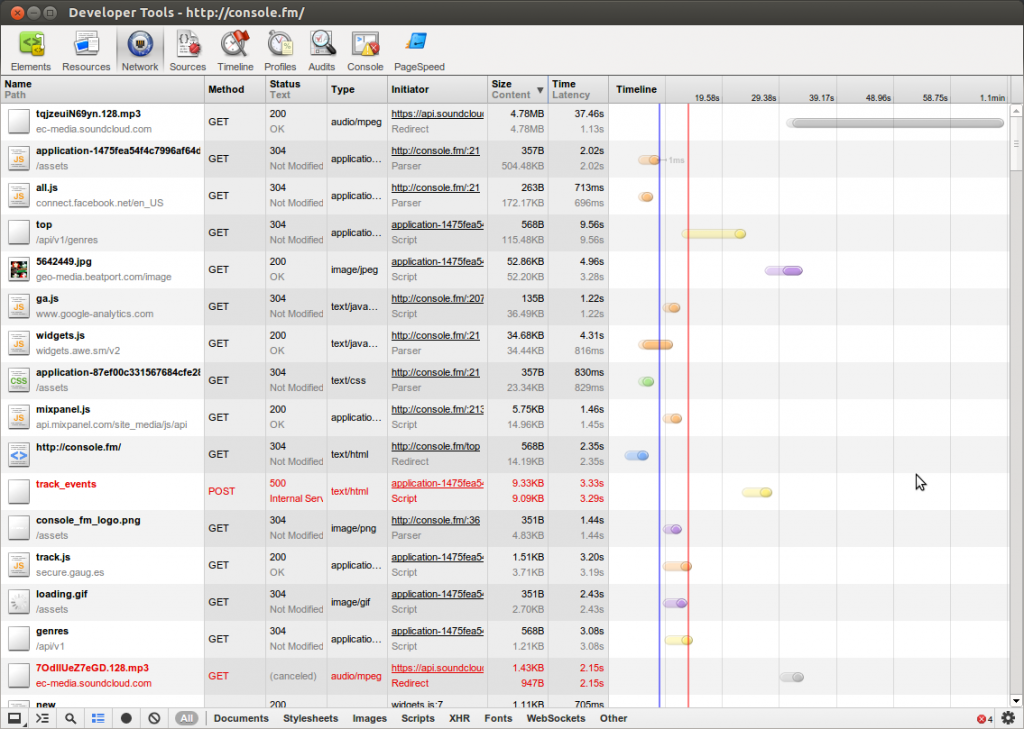
However, we see that the whole streamed file is downloaded into one mp3 in the cache:

So we know that Chrome already has what we look for, we just need to find a way for getting the file out of the cache.
Caching
Looking into the cache, all recently cached/downloaded files appear:
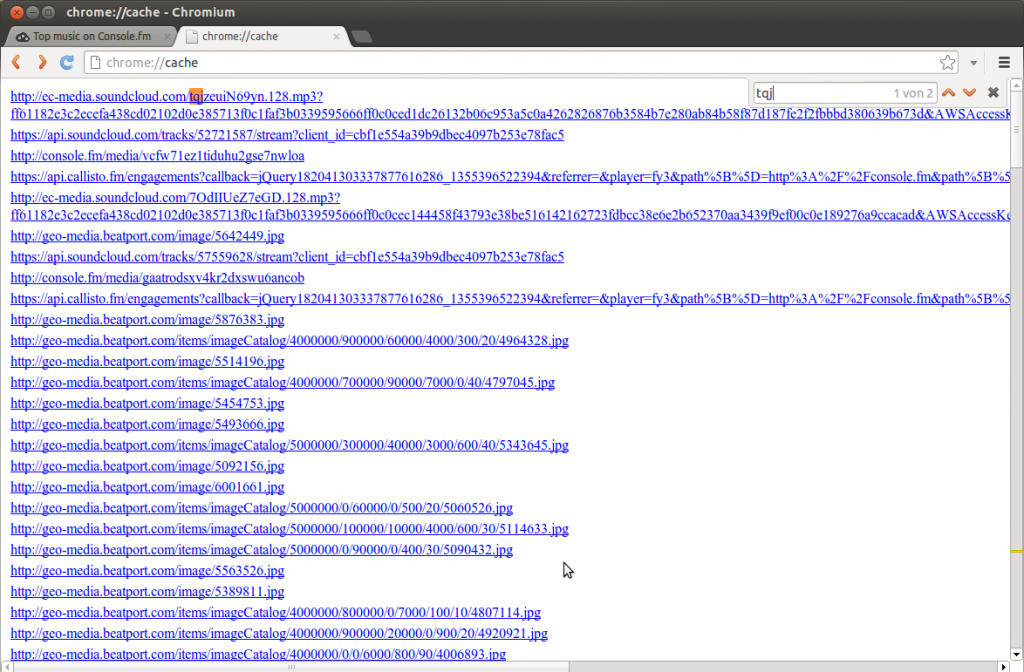
You can view the raw binary data of each entry. However, Chrome prepares them as follows:
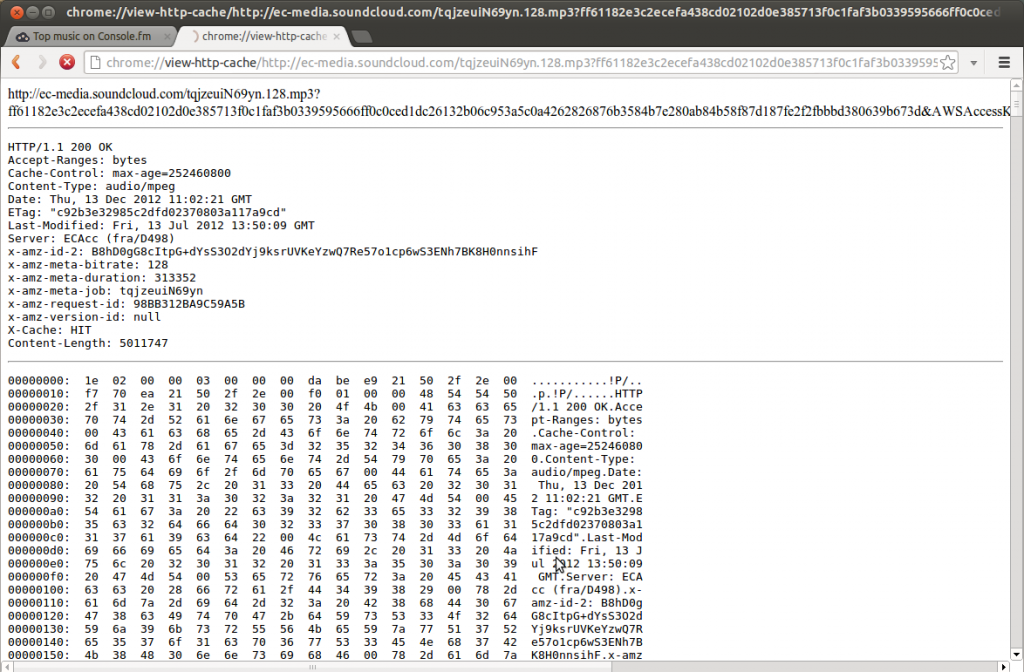
I guess they know what problems it would bear if they would offer a raw data dump of cached files. Nonetheless it's kinda odd that your own browser functions as an abstraction layer between you and a service, blocking you to get the raw data it received.
I found some Software for Windows and a Javascript Solution with 182 lines of code ("the easy way" :D). I tried to upload a mp3 file or to run the code in the console, but it didn't work. The cached HTML-site is somewhat around 25-30 MB and Javascript wasn't able to process it.
A bit of Python
Luckily, it's quite easy to extract the information from the given HTML-file. The data you want is all there, it just has to be written in a another form into a new file.
Python allows (like most of the time) a very simple approach: Split the file, and write the Hex-Code in the HTML-dump back into another file.
source = open(filename, 'rb')
content = source.read().split(pattern)[2].split("\")
source.close()
target = open(filename + ".mp3", 'wb')
for line in content:
l = line[:74].strip().split(" ")
del l[0]
for i in l:
target.write(chr(int(i, 16)))
target.close()It reads in the HTML file, then splits it into 3 parts (description, header, mp3 data) with the pattern
(you can look into the HTML-file from the cache to see why). After that, the mp3-data is split into lines and written into a new file.
This part
line[:74].strip().split(" ")cuts the first 74 characters from each line

and splits the Bytes into a list (the first element is the line number and will be deleted with del l[0]). As we have now access to the single bytes (in hexadecimal form) we can write them back using
target.write(chr(int(i, 16)))which first converts the hexadecimal into a decimal int and then writes back the ASCII character using chr().
How to download a song from console.fm/SoundCloud
- Open Google Chrome dev tools (ctrl + shift + i)
- Open console.fm and click on the song (load it in your browser, wait until loading has completed). Search for the song's name in dev tools (sort by size).

- Open the Chrome Cache with about:cache and search for the song
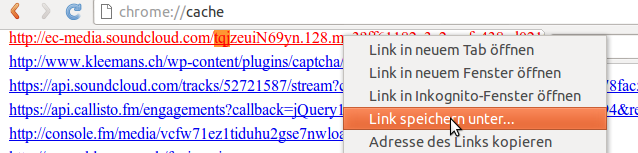
- Search for the song and save the html-file (right click -> save as)
- Run the python script with [code]python cache2file.py filename.html[/code] to get the mp3 file.

