Identifying language by letter frequency
Some time ago I was researching something about letter frequency in English (possibly for cracking some sort of decryption, I don't remember anymore) when I stumbled upon this table, Letter frequency in other languages:
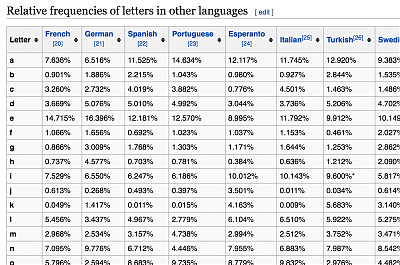
Part of the table at Wikipedia
I immediately wondered if it would be possible to identify some (preferably small) portion of text by its language, solely by looking at the letter frequencies. Obviously there are far more elaborated methods like word recognition etc., but the approach with letter frequency has two advantages:
- no language knowledge necessary (e.g. dictionaries or grammar rules) except for letter frequencies
- simple to implement: little code and measurable results
Hacking something together
(Code is on Github)
The basic idea is to first analyze the text and then calculate the mean squared error for each language, something like this:
- loop through text and calculate relative letter frequency (a: 3.3%, b: 2.1%, ....)
- for each language: 2a) load letter frequency for language 2b) compare frequency of each letter to frequency in text and add difference^2 to score for that language
- sort and output score for each language
Testing by example
Below are some text examples, and the mean squared error for each language (less is better):
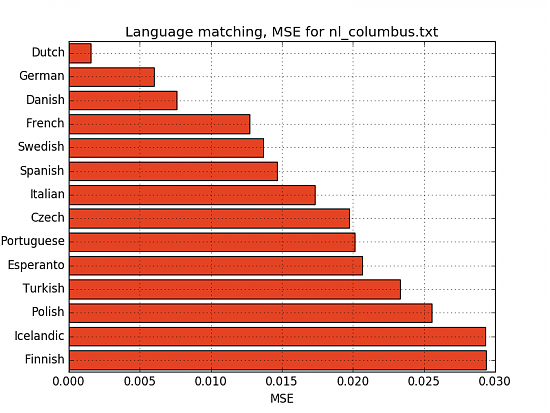
Columbus (Netherlands)
In de prachtige zeestad Genua, de trotsche bijgenaamd, werd omstreeks het jaar 1435 een knaapje geboren, dat nu in alle landen als Christophorus Columbus bekend is. (...)
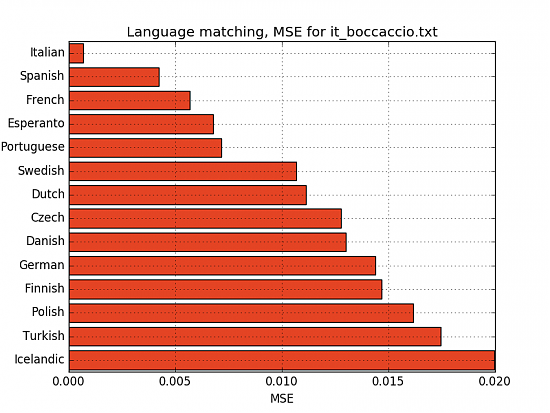
Boccaccio (Italian)
Solone, il cui petto un umano tempio di divina sapienzia fu reputato, e le cui sacratissime leggi sono ancora alli presenti uomini chiara testimonianza dell'antica giustizia, era, (...)
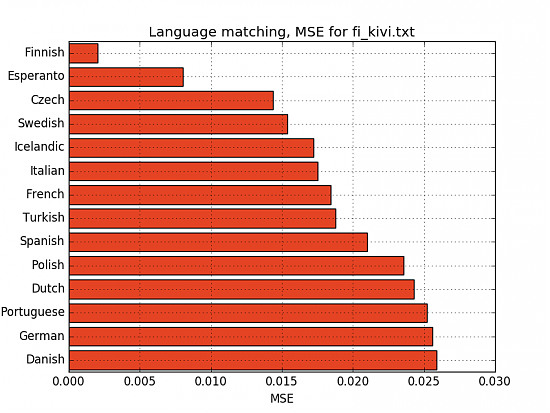
Kivi (Finnish)
Jukolan talo, eteläisessä Hämeessä, seisoo erään mäen pohjaisella rinteellä, liki Toukolan kylää. Sen läheisin ympäristö on kivinen tanner, mutta alempana alkaa pellot, joissa, (...)
The three snippets provided are from Project Gutenberg, each one contains only the first 200 lines of the original book.
Related languages
Interestingly enough, we also see which languages are similar to each other: For the italian text, spanish, french, esperanto and portuguese pop up first:
- Italian: MSE 0.0007 | 1503.6 points
- Spanish: MSE 0.0042 | 237.0 points
- French: MSE 0.0057 | 175.9 points
- Esperanto: MSE 0.0068 | 147.4 points
- Portuguese: MSE 0.0072 | 139.4 points
... while for the dutch text it's german and danish:
- Dutch: MSE 0.0016 | 639.8 points
- German: MSE 0.006 | 166.3 points
- Danish: MSE 0.0076 | 131.6 points
We can also see that Finnish is quite an outlier, with only Esperanto somewhere near it, and all other languages are quit far away.
Conclusion
With a simple Python script and the table from Wikipedia we get some quite good results on our example texts! It is, however, quite a small subset of languages we're checking here, so maybe a bigger set would reveal some more results.
Furthermore we also get some "relative" results how the languages stand to each other and how close they match the occurring frequencies of the example text.
Thanks for reading!
