Pivoting a table
Last time I wrote about Recursive SQL, this time I'd like to share my experience with the use of Oracle's PIVOT, which came in handy last time when querying a large database full of measurement data.
The data consisted of single measurement entries (something with measuring latency and bandwidth), each of them had (amongst other attributes) a timestamp and a place where the data was from, let's say from a site:
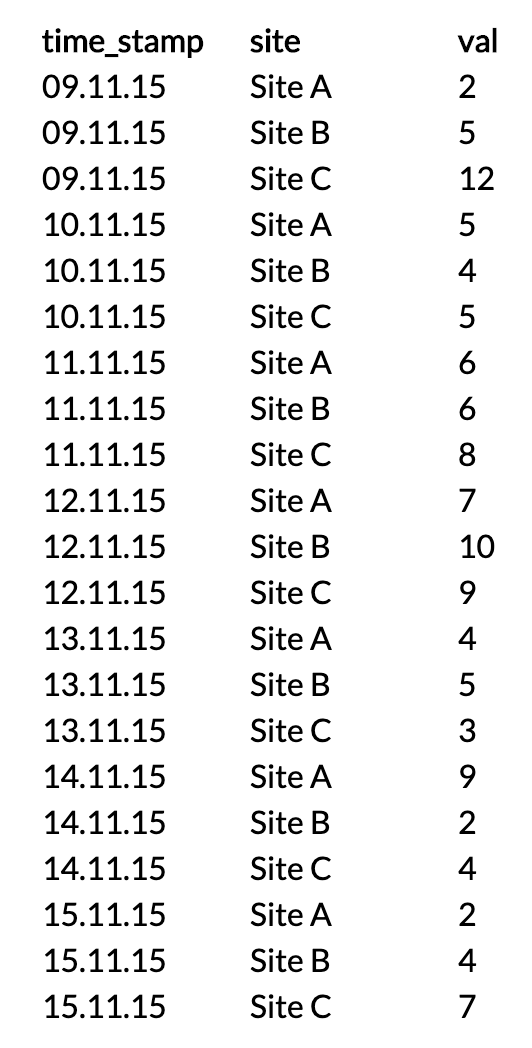
Table measurements
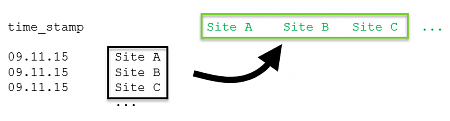
The problem was that the data should be presented as a matrix in the following way, with one row per date:

Other tools were relying on a certain format and the workflow would break if the data wouldn't fit. Understandably, the data in the list format is less readable (especially because we had like 30 sites) and also much longer than expected, because each value had a separate row.
Reformatting a list into a matrix
Googling a bit around I found this post on StackOverflow which shows how Oracle's PIVOT function works, which does exactly what was asked for in quite a elegant way, turning rows into columns (simply said).
It works like this:
SELECT *
FROM measurements
PIVOT (MAX(val) FOR site IN ('Site A', 'Site B', 'Site C'))Notice the grouping function MAX? If you have multiple entries for a certain site with the same time stamp, you could decide how to aggregate those using the standard oracle functions (COUNT, SUM, AVG, ...). Luckily I knew for sure that I would have only one measurement per time_stamp and site (or none), so I didn't have to decide how to handle multiple entries, I just went with MAX.
Using a subquery
Using it the first time yielded some strange results though:
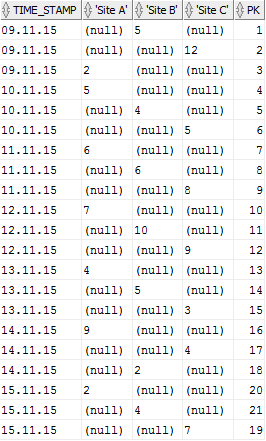
Because the rows were all different (each row had a primary key), the data could not be grouped. Using a subquery and just mashing the pure data together worked and the query looked like the following:
WITH tmp_data AS (
SELECT time_stamp, site, val
FROM measurements
ORDER BY time_stamp, site ASC
)
SELECT *
FROM tmp_data
PIVOT (MAX(val) FOR site IN ('Site A', 'Site B', 'Site C'))
ORDER BY time_stampResult:
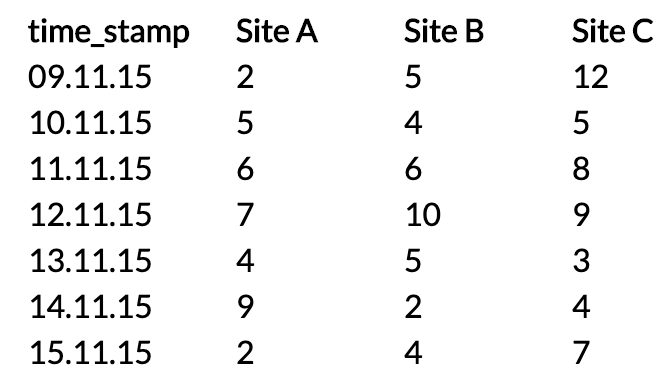
In the FOR site IN (...) part, you can even define your own aliases:
PIVOT (MAX(val) FOR site IN (
'Site A' "SITE_A",
'Site B' "SITE_B",
'Site C' "SITE_C"
))Dynamic data
Until now, we had to define the possible values of the site column, like Site A, Site B or Site C. But the query had to be robust and also include new sites without changing the scipt each time, so we had to dynamically check what sites are present in the list.
Unfortunately, the use of a subquery in the IN clause like
PIVOT (MAX(val) FOR site IN
(SELECT DISTINCT site FROM measurements) )doesn't work, because a subquery is only allowed with PIVOT XML, as we found out after first trying and then reading the PIVOT docs. This will generate a single column with XML code instead of multiple columns:
<PivotSet><item><column name = "SITE">Site A</column>...We eventually ended up with another query around our original query, which did the job of finding the existing site values and wrote them as a string in the IN-clause. Let's wait for Oracle 12 and check out its possibilities :-)
Thanks for reading!
