Use private data with a LLM / GPT
Large language models (LLM) like GPT-4 and their applications (like ChatGPT) are great for querying common, public data. But what about using private data like a personal text corpus, corporate data or a private wiki?
To do this there are basically three options:
- Train a custom model based on your data: While this might yield the best results, this will also be the most expensive (and technically challenging) option by far.
- Add the data as a prefix to the actual prompt: As the "context windows" get increasingly bigger (ChatGPT with GPT-4 can handle around 8k tokens), we could append the data as "Given:
answer the following prompt: ". This puts a hard constraint on how much data we can actually use. - Provide only the most relevant bits of data additionally to the prompt. As we will be seeing below, an index can be built and the most relevant context will be used with the prompt.
In this post we're going to use LlamaIndex, which uses the third option. On a high level, it works like this:
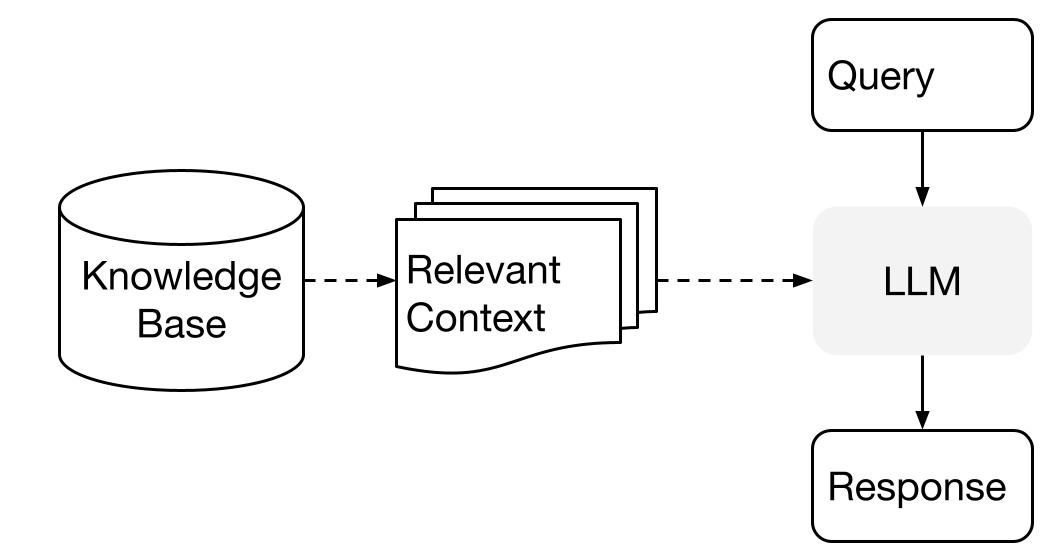
(Image from llama-index documentation)
We'll learn how to prepare the "relevant context" as an index, store it and use it for querying GPT.
Create an OpenAI API key
For this to work, you'll need an API key by OpenAI. You can do so here: platform.openai.com/account/api-keys.
I only got it to work with a paid subscription, but the good thing is that you can set a usage limit of like $10 to make sure nothing goes wrong.
Prepare the data
To play around we're going to use a single blog post of myself, kleemans.ch/game-boy, and ask questions based on the content.
We'll just copy over the contents of the blog post into a simple text file (without images). For bigger data sources, instead of copying together all the text, you can use adapters (available on Llama Hub), for example to access Github, Confluence or alike.
So to start, we'll create a directory "data" with a single text file game_boy.md.
Game Boy
April 26, 2021
This post is part of the Game Boy series (#1).
This post starts a series about and around the Game Boy
(...)The data we're going to provide is text only, but it doesn't matter if the file is .txt, .md or alike.
Creating the index
Now that we have the data, let's build the index! To start, we'll need to install llama-index, for example via pip:
pip install llama-indexAfter that, we can start to prepare the index. We'll create a Python script called generate_index.py:
import os
os.environ["OPENAI_API_KEY"] = 'sk-...'
from llama_index import VectorStoreIndex, SimpleDirectoryReader, ServiceContext
documents = SimpleDirectoryReader('data').load_data()
service_context = ServiceContext.from_defaults(chunk_size=256)
index = VectorStoreIndex.from_documents(
documents,
service_context=service_context,
show_progress=True
)
index.storage_context.persist(persist_dir="index")This will parse the data into so-called nodes and generate embeddings which can then be used for querying.
Side note: I had to use the chunk_size=256 parameter to make it work, because I ran into a RateLimitError when using a higher chunk size (or none at all).
Querying
For querying, we'll first load the index and then send a query to it. Let's create a script query.py and run it:
import os
os.environ["OPENAI_API_KEY"] = 'sk-...'
from llama_index import StorageContext, load_index_from_storage
storage_context = StorageContext.from_defaults(persist_dir='index')
index = load_index_from_storage(storage_context)
query_engine = index.as_query_engine()
while True:
query = input('Enter query: ')
if query == 'q': break
response = query_engine.query(query)
print(str(response).strip())Let's try it!
Enter query: What is the post about?
This post is about the Game Boy, a gaming console from the late 80s/90s, and the author's memories of playing it. The post also discusses the portability of the Game Boy and how the author used it during trips and camping holidays. Finally, the post mentions the author's experience with playing old games and trying to speedrun them.
Enter query: Does the author have any favourite games? Please list exactly two.
Yes, the author has two favourite games: Pokémon and Super Mario Land.
Enter query: Where did the author get his GameBoy from?
The author got his Game Boy from a market.Nice! It feels as if the LLM really read & understood the post and can answer questions in detail.
Side note: API usage
By the way, how does this reflect in API calls? The library, llama_index, does a pretty good job in abstracting away the interaction with the OpenAI API. But we can have a look on the "Usage" tab:
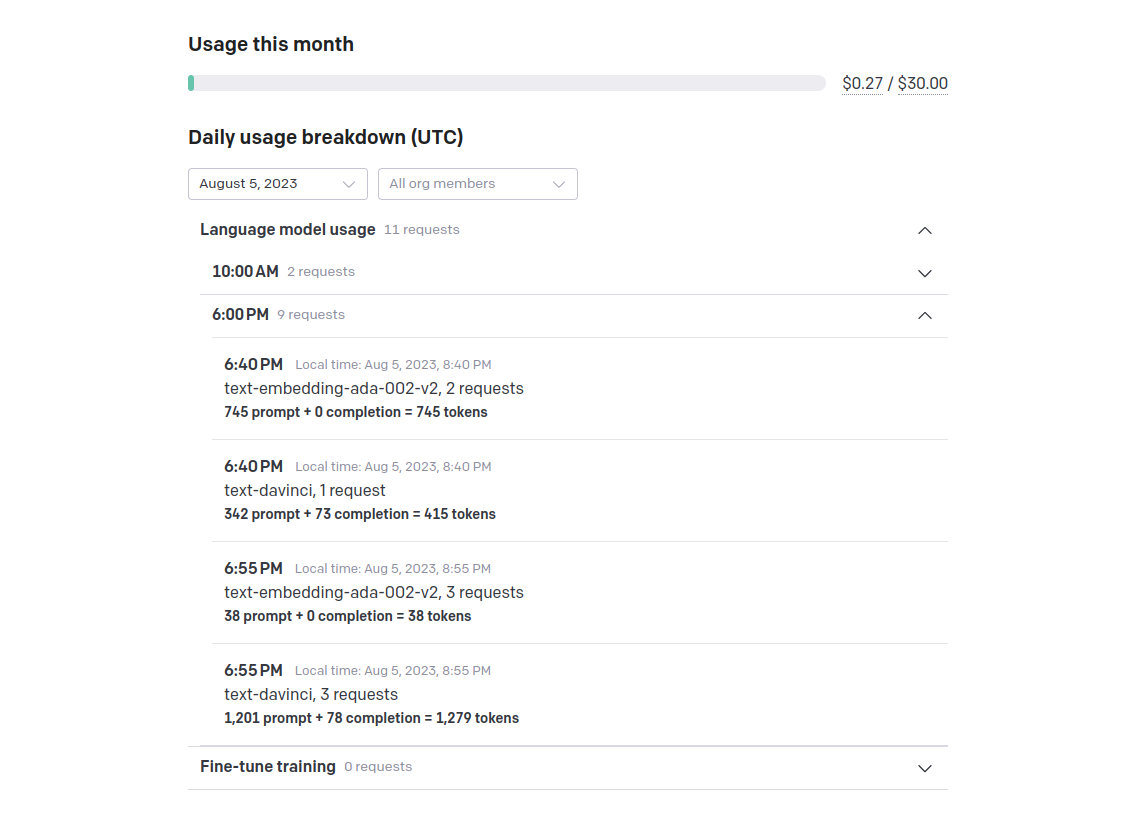
It seems to use both text-davinci and text-embedding-ada-002-v3.
Thanks for reading and happy indexing!
